Web Hacking
Este paper irá abordar:
Básico de HTTP.
Reconhecimento de diretórios de website.
Brute force de áreas de login. ( curl )
Trabalhando com Cookies.
Trabalhando com User-Agents
WebCrawling
Buscando Emails
Buscando hosts de dominios
Site Clone
Trabalhando com Json
Trabalhando com xml
Básico de HTTP
Antes de avançarmos sobre HTTP, eu gostaria só de passar umas informações básicas sobre como o protocolo HTTP e HTTPS funciona.
A principio, ambos funcionam da mesma forma porém HTTPS implementa criptografia. O foco aqui é no protocolo em si, como ele funciona e de suma importância os status code que ele retorna.
A imagem abaixo vai ilustrar um exemplo: 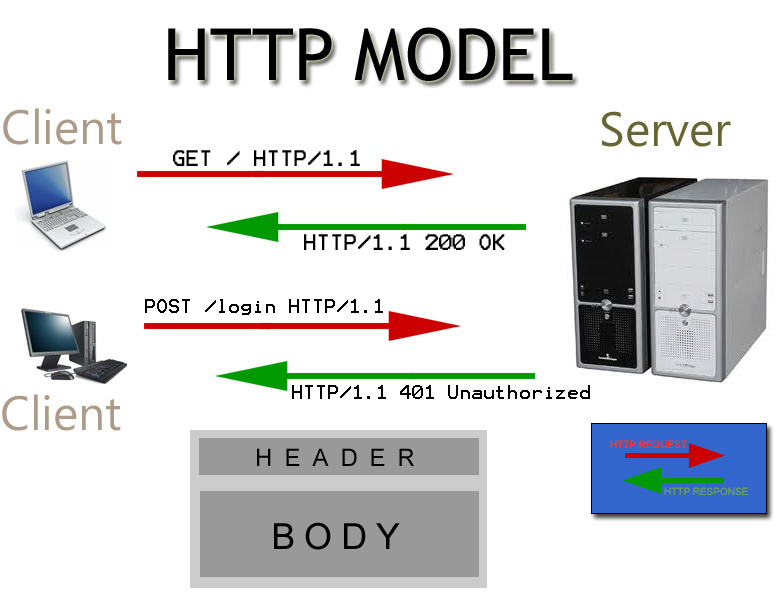
Em requisições web e em todoos os tipos de requisições nós sempre temos o cliente e o servidor. No contexto web, um cliente requisita geralmente uma requisição GET da index do webserver. O Servidor sempre um status code para o cliente e geralmente retorna o que o cliente solicitou.
Esses status code tem relação com algumas coisas, segue uma tabela: 
Conforme a primeira imagem é possível ver que o servidor retorna o código 200 OK , que de acordo a tabela significa sucesso.
Outros status code podem ser obtidos, por exemplo, quando se tenta acessar um diretório que não existe você obtem um status code 404 Not Found.
Nós iremos trabalhar explicitamente com esses códigos de status durante esse paper, principalmente na parte de bruteforce de diretórios.
Reconhecimento de diretórios de website. ( curl/wget )
Nesse tópico iremos entrar em reconhecimento de diretórios e websites, vamos estar trabalhando basicamente com bruteforce mais além nesse mesmo paper irei abordar uma forma diferente de fazer tal reconhecimento que pode ser mais eficiente ou não.
Vamos ter em mente o seguinte, toda vez que nós tentamos acessar um diretório que existe ele retorna 200 OK
A flag s é para silent, para o curl não dumpar dados de conexão e a flag -I é para pegar apenas o HEADER da resposta da requisição, então redirecionamos e com o comando head nós pegamos apenas a primeira linha que é a linha qual contém as informações do status code, no caso foi HTTP/1.1 200 OK
Se tentarmos acessar um diretório/página que não existe, teremos um outro código de status:
Se tentarmos acessar um diretório que existe porém não tem nenhum index configurado e o webserver não tiver com a configuração erronea de IndexOf, o erro que vai retornar é outro:
Nesse caso obtivemos o status code de retorno HTTP/1.1 403 Forbidden, então o diretório existe. Método 401 -> Authentication Required Então um script de enumeração fica fácil, é só fazer os mesmos testes que realizamos porém de forma automatizada, caso retorne 200 ou 403, sabemos que existe.
Exercicio
Solução
O código acima não faz nada alienigena, só coloquei algumas coisas que não falei antes nesses papers mais vou explicar detalhadamente.
Na linha abaixo eu salvo o status code da requisição HTTP na variável STATUS_CODE, o cut utilizado foi para pegar o valor do código apenas.
Na linha abaixo eu utilizei uns truques do echo para sobreescrever a linha, deixando um output mais interessante:
O programa fica exibindo qual URL ele está testando na mesma linha, quando uma requisição retorna o código desejado ele salva o texto na linha sobreescrevendo a mesma linha e pula pra próxima linha quando cai do else. Truque que deixa o programa com uma cara mais bonita no runtime!
A wordlist você pode por exemplo utilizar as wordlists do dirb, é um programa que faz praticamente a mesma coisa que nosso script porém com umas features a mais, ele tem umas wordlists já prontas e uma vez instalado as wordlists se encontram no diretório /usr/share/dirb/wordlists
Ou vocẽ pode utilizar a sua própria wordlist de acordo com o que você encontrar por ai!
Para executar o programa faça assim:
Bom, sobre enumeração de diretórios atŕaves de bruteforce é isso, iremos dar uma olhada em outras técnicas ainda nesse paper mais à frente sobre técnicas mais refinadas de enumeração utilizando web crawler.
O cURL é tão irado que de acordo com a documentação você pode realizar ataques da seguinte forma:
Brute force em áreas de login.
Outra coisa que pode ser util geralmente em casos de desespero é o BruteForce, o shellscript é tão poderoso que te permite realizar bruteforce em aplicações web que não provêm de mecanismos de proteção contra tal técnica.
Em casos que o alvo possua mecanismos para mitigar/bloquear ataques de BruteForce, você pode adotar várias técnicas para confundir a ferramenta de proteção como por exemplo utilizar diferentes User-Agents de forma aleatória, trocar o endereço IPv4 atráves de instâncias da rede tor ou proxys.
Para essa parte eu escrevi um pouco de html/PHP para fazer um ambiente controlado.
Segue abaixo a index.html:
Agora o formulário checkForm.php:
Nesse caso eu não subi um banco de dados mas isso é irrelevante para os testes. Nesse primeiro exemplo vamos estar explorando um formulário que utiliza o método GET de requisição, o que isso quer dizer? O método GET passa as requisições pela URL, ou seja, em texto plano. Vamos fazer um hands on e você vai entender.
Uma vez que você tenha acessado o formulário num webserver, e entrar com os dados no formulário e clicar em Submit, você pode notar a seguinte alteração na URL:
Repare que os dados que você inseriu nos campos username e password no formulário foram passados em texto plano na URL, caso você altere qualquer um dos campos da URL e dê enter, uma nova requisição será feita.
Outra forma de identificar quais são os campos do formulário é abrir o source da página, isso pode ser feito teclando ctrl^u ou inserindo na url no começo view-source: da seguinte forma:
Uma vez feito isso basta analisar o código do formulário. Outra forma também é clicar com o botão direito do mouse e ir em inspect element e logo em seguida ir na aba Network, deixe essa console aberta e volte no formulário na mesma do navegador e então realize o submit no formulário, você verá que as requisições apareceram na console, então selecione a requisição cujo campo FILE esteja com o script de action visto no formulário anteriormente:
Então você pode ir em Params e avaliar os parâmetros passados para o script.
Bom, nesse caso já temos o necessário para começar a escrever o programa de BruteForce no formulário.
Então avaliando o manual do comando cURL você pode notar que existem várias formas de fazer a mesma coisa com o mesmo comando, vou estar mostrando a mais simples.
Vou estar usando a própria URL para realizar o ataque, como você viu anteriormente os dados passam em texto plano então não é necessário muita coisa além de alguns loops.
Lets Roll!11!
No código anterior nós realizamos um ataque direto na URL aproveitando o metódo GET. Eu adicionei várias verificações no código e no cabeçalho do mesmo eu deixei um desafio para você. Sinta-se a vontade para passar horas codificando!
O outro método de transmitir valores para o action é atráves do método POST, ao contrário do GET o post não passar os dados via URL. Mais uma vez se analizarmos a documentação do cURL podemos ver que ele possui especificamente formas de se realizar esse tipo de interação:
Para esse laboratório vai ser necessário realizar pequenas alterações no nosso website, segue a index.html:
Se você analisar agora quando clicar em SUBMIT vai identificar que os dados do formulário não mais é passado pela URL e como já explicado anteriormente é asssim que o método POST opera. Bom e para realizar ataques à aplicações POST?
Vamos fazer um handson, lets code!
Sobre Cookies.
Cookies são usados para identificar usuários, é um pequeno arquivo que fica armazenado no computador do usuário. Cada vez que um memso computador requisita uma página web atráves de um browser, será encaminhado um cookie também. Cookies são usados não apenas para identificar usuários mas para controle de sessão, preferências e muitas vezes é utilizado para redrecionar propaganda.
Por que isso é importante? Vamos supor que você precise fazer um teste em uma aplicação porém precise estar logado para realizar tal teste. Quando você loga em alguma aplicação você vai ter um cookie que vai conter a sessão do seu login, sem o cookie o sistema identifica que você não está logado. Com o cookie os sistema reconhece seu login. Isso é tão legal que se você pegar o cookie e colocar em outro browser ou outro computador vai ser capaz de abrir a sessão do usuário desde que o cookie não tenha expirado.
O cURL também trabalha com cookies, de acordo com o manual:
Os arquivos de cookies são armazenados num banco sqlite pelo firefox, segue abaixo:
Você poderia entrar naquele banco de dados porém ele irá estar em lock pois estará em uso por outro processo caso o navegador esteja aberto e você não irá conseguir interagir.
Então como fazer isso? Abaixo tem as formas possíveis de trabalhar com cookies usando o cURL
https://www.w3schools.com/php/php_cookies.asp
Trabalhando com User-Agents
Um user-agent é a identificação do cliente do usuário que acessa um determinado sistema. Nas requisições como nós já vimos anteriormente é possível ver que os browsers por exemplo informam qual é o user-agent que está requisitando determinada página.
O cURL também tem capacidade de operar com user-agents nas requisições, observe:
WebCrawling
Web Crawler ou em português rastreador de rede, é um programa de computador que navega pela rede mundial de uma forma metódica e automatizada.
Vocẽ pode por exemplo escrever um programa para fazer crawler atrás de e-mails ou números de telefone. Esses programas abrem uma página web e procuram por padrões, que podem ser outras páginas web ou simplesmente emails, números de telefone, endereços etc.
Exemplos de web Crawlers
Yahoo! Sluro é o nome do Crawler do Yahoo!
Msnbot é o nome do Crawler do Bing – Microsoft.
Googlebot é o nome do Crawler do Google.
Methabot é um Crawler com suporte a scripting escrito em C.
Arachnode.net é um Web Crawler open-source usando a plataforma .NET e escrito em C#
DuckDuckBot é o Web Crawler do DuckDuckGo.
Aqui iremos abordar a criação de dois tipos, o primeiro vai ser para detectar endereços de e-mail.
Para concluir essa tarefa vamos dar uma passada breve em regularExpression. Mas o que é isso?
Uma expressão regular(regex, regexp) é uma string de texto especial que realiza buscas em texto atráves de padrão.
O asterisco sozinho não diz nada, ele é apenas um repetidor que precisa de algo antes, como em . ou [0-9]. Não confundir com file globin.
Pesquisando por nomes que começam com vogais.
Negação:
Ignorando a primeira letra e a segundo sendo uma vogal.
What?:
As chaves
As expressẽos regulares nos dão ferramentas mais flexíveis para fazer a pesquisa. Colocando um número entre chaves, indica-se uma quantidade de repetições do caractere(ou metacaractere) anterior: egrep '^.{27}$' /etc/passwd
As chaves fazem parte de um conjunto avançado de expressões regulares(extended) e o egrep lida melhor com elas, se fosse para utilizar o grep normal seria necessário escapar as chaves grep '^.{27}$' /etc/passwd
Combinando metacaracteres:
O Curinga . (AND) Procura por usuários cujo nome começa com vogal e que o shell seja o bash: egrep '^[aeiou].bash$' /etc/passwd
Funciona como um AND lógico.
OR Lógico
Outros metacaracteres --> * + ? ? -> {0,1}
-> {0,}
-> {1,}
Lugares que você pode estar praticando:
Pacote txt2regex
regexpal.com
regex101.com
Vamos ao coding!
Bom, nós podemos aplicar o crawler para encontrar diretórios no website a partir da index, vamos ver como ficaria um código disso:
Um outro programa para identificat hosts de dominio dentro da index do website do alvo é o seguinte:
Algumas outras dicas para tratamento de texto:
Removendo tags:
Sem aspas no href:
A ideia é padronizar o arquivo, por exemplo, remover todas as aspas e passar tudo pra minusculo, substituir quebras de linha por espaços em branco, assim você não precisa ficar alterando o código que extrai os dados.
Ferramenta chamada tidy -> Arrumar e alinhas códigos HTML/XML.
Lynx The Cli Browser
Principais opções:
dump -> Renderiza uma página HTML e manda para STDOUT
source -> Baixa o Fonte HTML de uma página e manda para STDOUT
nolist -> Usado com o -dump, para omitir a listagem de links
width -> Define a largura máxima do texto, o padrão é 80
Site Clone
A clonagem de websites é muito útil em ataques de engenharia social, onde você faz o seu alvo acreditar que está acessando o site legitimo porém é um site clonado que vocẽ fez.
Existem muitas ferramentas já prontas com isso, um exemplo é o SET. Aqui iremos estar desenvolvendo um programa que clona websites a partir do programa wget.
Aqui nós podemos utilizar um dos programas que nós criamos anteriormente que identificava os diretórios do website, então quando um diretório é identificado nós podemos efetuar o download do mesmo realizando a clonagem.
A opção -m do wget permite realizar a clonagem de forma recursiva.
Last updated